

Blog DNC
Encontre conteúdos completos em diversas áreas com dicas práticas, guias passo a passo, cases de mercado e insights para quem quer evoluir de verdade.



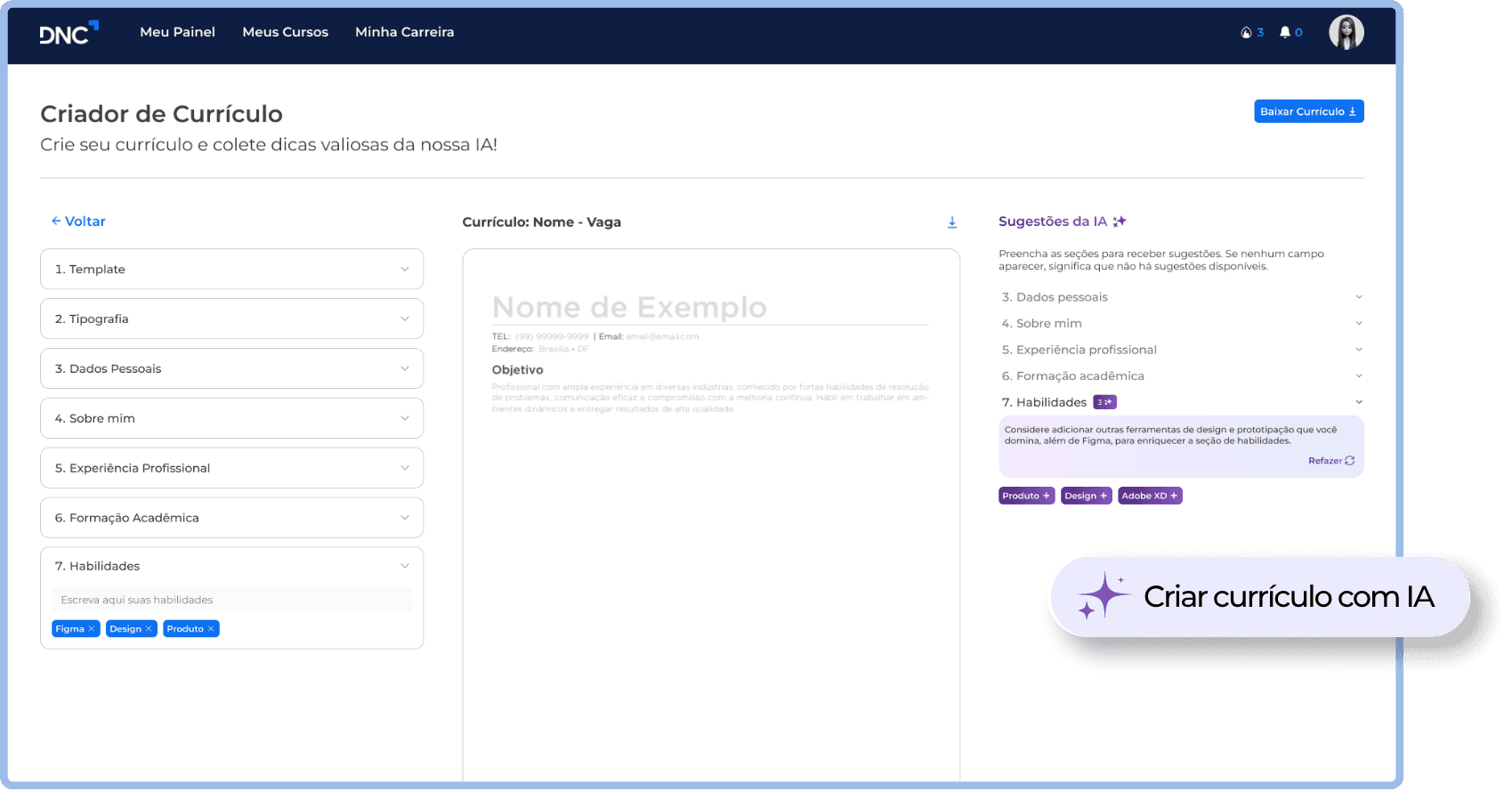

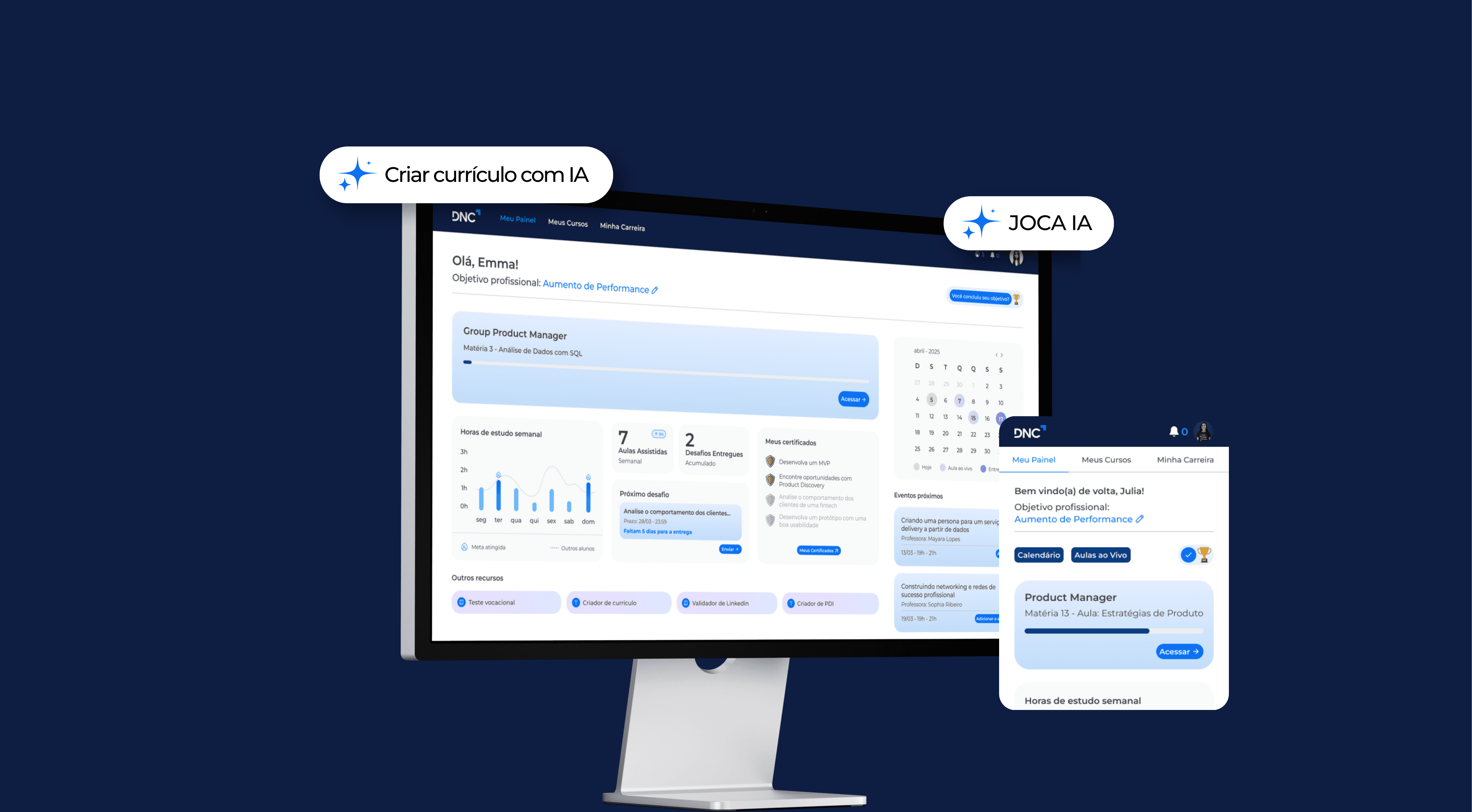






DNC News
Inscreva-se na nossa newsletter exclusiva e receba dicas para acelerar seu crescimento profissional toda semana!
Inscreva-se agora!
DNC News
Inscreva-se na nossa newsletter exclusiva e receba dicas para acelerar seu crescimento profissional toda semana!
Inscreva-se agora!
DNC News
Inscreva-se na nossa newsletter exclusiva e receba dicas para acelerar seu crescimento profissional toda semana!